
After the extinctions … at least our kids will always have the dominoes por woodleywonderworks (CC-BY) Lo primero que quiero hacer constar es que toda la argumentación de esta entrada es desde el punto de vista de un docente, con una visión IANAL (I am not a lawyer). A raíz de la anterior entrada de este blog «Consulta …
Categoría: Internet
Nov 10
Consulta sobre compatibilidades de las licencias Creative Commons

http://www.flickr.com/photos/fannynetes/2991807152/ // BY-NC-SA Hoy me han hecho una consulta sobre la licencia que deberíamos poner a una obra si queremos incluir fotografías con licencia CC-BY-SA en algún trabajo nuestro. La respuesta es sencilla: «la única licencia compatible con CC-BY-SA es ella misma«. Podéis encontrar más información en el capítulo dedicado a este problema del sitio …
Jul 10
Instagram y Creative Commons

Hace unos días, descubrí una foto en Instagram de una amiga que me podría servir para el tablero de «Escritura Creativa«. Comprobé que en Instagram no hay forma de poner una licencia a las imágenes por lo que la licencia que tienen, de acuerdo a nuestra LPI, es copyright. O sea todos los derechos reservados. …
Oct 04
Web de aspectos legales en la educación

Foto de h.koppdelaney compartida con licencia cc El motivo de esta entrada es compartir con vosotros un material que cree hace algún tiempo sobre los aspectos legales del uso de las TIC en la educación. Este tema ya ha sido tratado en el blog, debido al taller que impartí en Aulablog13, pero lo que ahora …
Jul 25
#aulablog13 Aspectos legales de las TIC en Educación

photo credit: opensourceway via photopin cc En el post anterior, describí uno de los talleres que impartí en aulablog13 y me obligué a escribir otro post en el que explicará el otro taller que impartí titulado «Aspectos legales de las TIC en Educación«. Desde mi punto de vista este es un tema que todos los que usamos la red …
May 06
20 Things I Learned, excelente libro sobre internet

20 Things I Learned es un experimento hecho por Google, a modo de demostración de lo que es posible hacer con HTML5. Como valor añadido, nada despreciable, Google nos ofreció un excelente libro en el que podemos encontrar 20 temas sobre internet y la web expuestos con claridad y sencillez en una interfaz muy agradable …
Dic 28
Organizar la información en internet (III)- Inocentada

Este artículo era una broma por el día de los Santos Inocentes 🙂 Todo lo que está en rojo es parte de la broma. Este es el tercer y último artículo dedicado a la tarea de organizar la ingesta de información en la red. En el primer artículo vimos las ventajas de las suscripciones a …
Dic 21
Organizar la información en Internet (II)
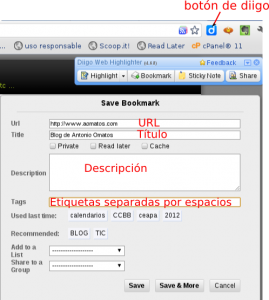
En el anterior artículo vimos un método para optimizar nuestro acceso a blogs, sitios de noticias, etc. mediante el uso de los agregadores o lectores de RSS. Tal y como planteaba, el paso siguiente, sería decidir el procedimiento que usamos para recopilar y archivar la información que consideremos importante. Todo buen archivado tiene que partir …
Licencia:

Blog de Antonio Omatos se comparte bajo una licencia Creative Commons Reconocimiento-NoComercial-CompartirIgual 3.0 España License.